01
Iterative exploration
RoboEXP can zero-shot explore unseen real-world environments, reveal hidden structure through interaction, and reuse the resulting memory for downstream manipulation.
We introduce the task of interactive scene exploration, where a robot autonomously explores an environment and produces an Action-Conditioned Scene Graph (ACSG) that captures its underlying structure. Unlike a static reconstruction, the ACSG records both low-level geometry and semantics and high-level relationships that only become visible through physical interaction.
RoboEXP combines a Large Multimodal Model with an explicit memory design. It reasons about what to explore, how to interact, and when new evidence should update its model of the scene.
Interactive exploration constructs the ACSG; the same graph then supports the downstream table-setting task.
A closed loop between perception, explicit memory, decision-making, and physical action.
Starting from RGB-D observations, vision foundation models ground objects while the memory module fuses observations into the ACSG. A decision-making module reasons over that graph to propose the next exploration plan, and the action module executes it. Every interaction returns new evidence to the same structured memory.
The high-level graph remains actionable while low-level memory anchors its nodes and relationships in 3D.
Objects and action-conditioned relationships are added as the robot explores.
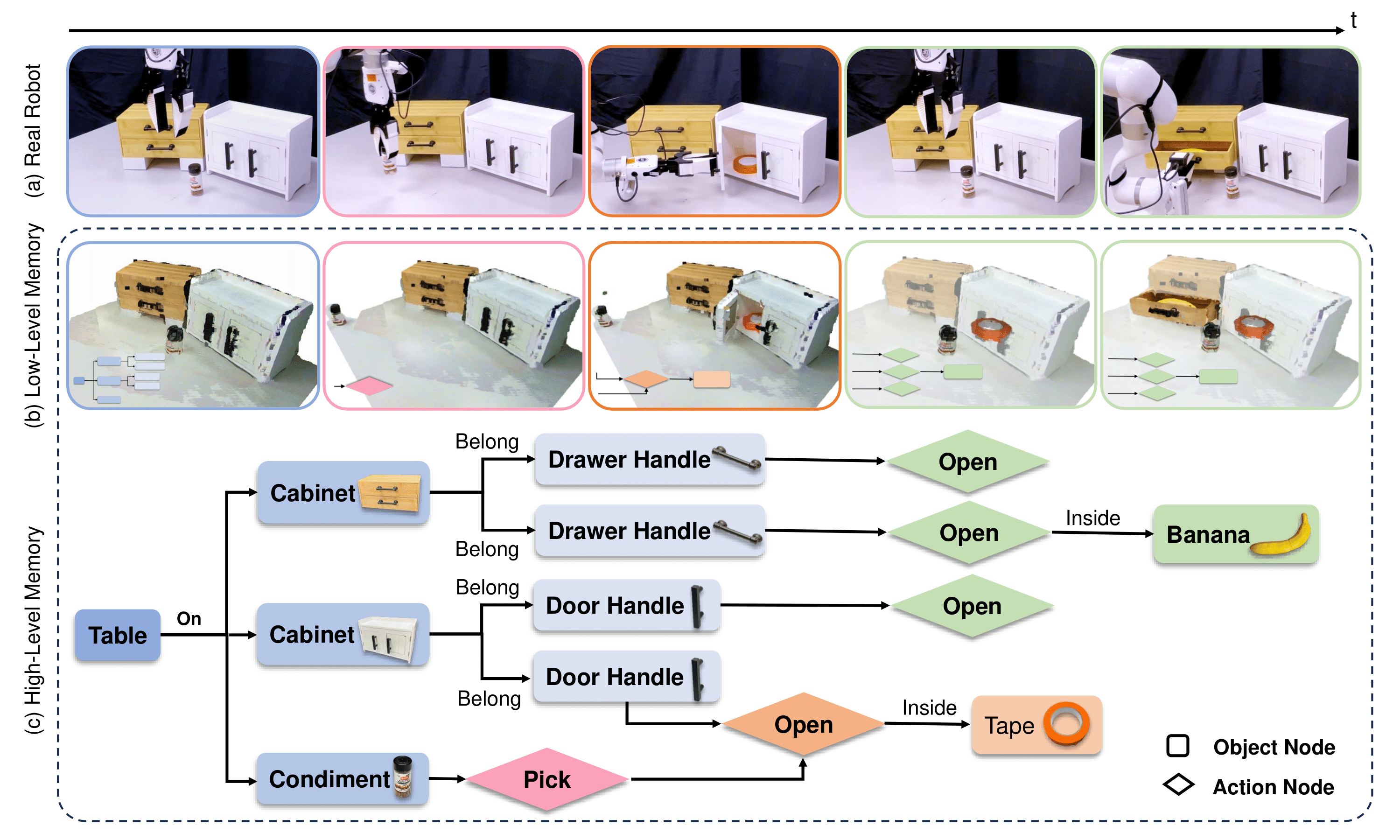
Geometry and semantic observations ground graph reasoning in the physical scene.
RoboEXP detects new or moved objects, identifies the affected region, and selectively re-explores it.
01 Detect the new structure and extend the scene graph.
02 Track the change and re-explore only where needed.
The interactive exploration pipeline transfers to a Stretch mobile manipulator for household scenarios.
01 Open articulated storage to discover what is inside.
02 Interact with deformable objects to reveal hidden items.
Zero-shot exploration with rigid, articulated, nested, occluded, and deformable objects.
From autonomous exploration to graph construction and downstream manipulation.
If RoboEXP supports your research, please cite the CoRL 2024 paper.
@inproceedings{jiang2024roboexp,
title = {RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation},
author = {Jiang, Hanxiao and Huang, Binghao and Wu, Ruihai and Li, Zhuoran and Garg, Shubham and Nayyeri, Hooshang and Wang, Shenlong and Li, Yunzhu},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2024}
}